
-
- Downloads
Initial commit
parents
No related branches found
No related tags found
Showing
- README.md 54 additions, 0 deletionsREADME.md
- RL_brain.py 16 additions, 0 deletionsRL_brain.py
- RL_brainsample_PI.py 55 additions, 0 deletionsRL_brainsample_PI.py
- maze_env.py 180 additions, 0 deletionsmaze_env.py
- plot.png 0 additions, 0 deletionsplot.png
- plotzoom.png 0 additions, 0 deletionsplotzoom.png
- run_main.py 155 additions, 0 deletionsrun_main.py
- task1.png 0 additions, 0 deletionstask1.png
- task2.png 0 additions, 0 deletionstask2.png
- task3.png 0 additions, 0 deletionstask3.png
README.md
0 → 100644
RL_brain.py
0 → 100644
RL_brainsample_PI.py
0 → 100644
maze_env.py
0 → 100644
plot.png
0 → 100644
{kind=link}

266 KiB
plotzoom.png
0 → 100644
{kind=link}
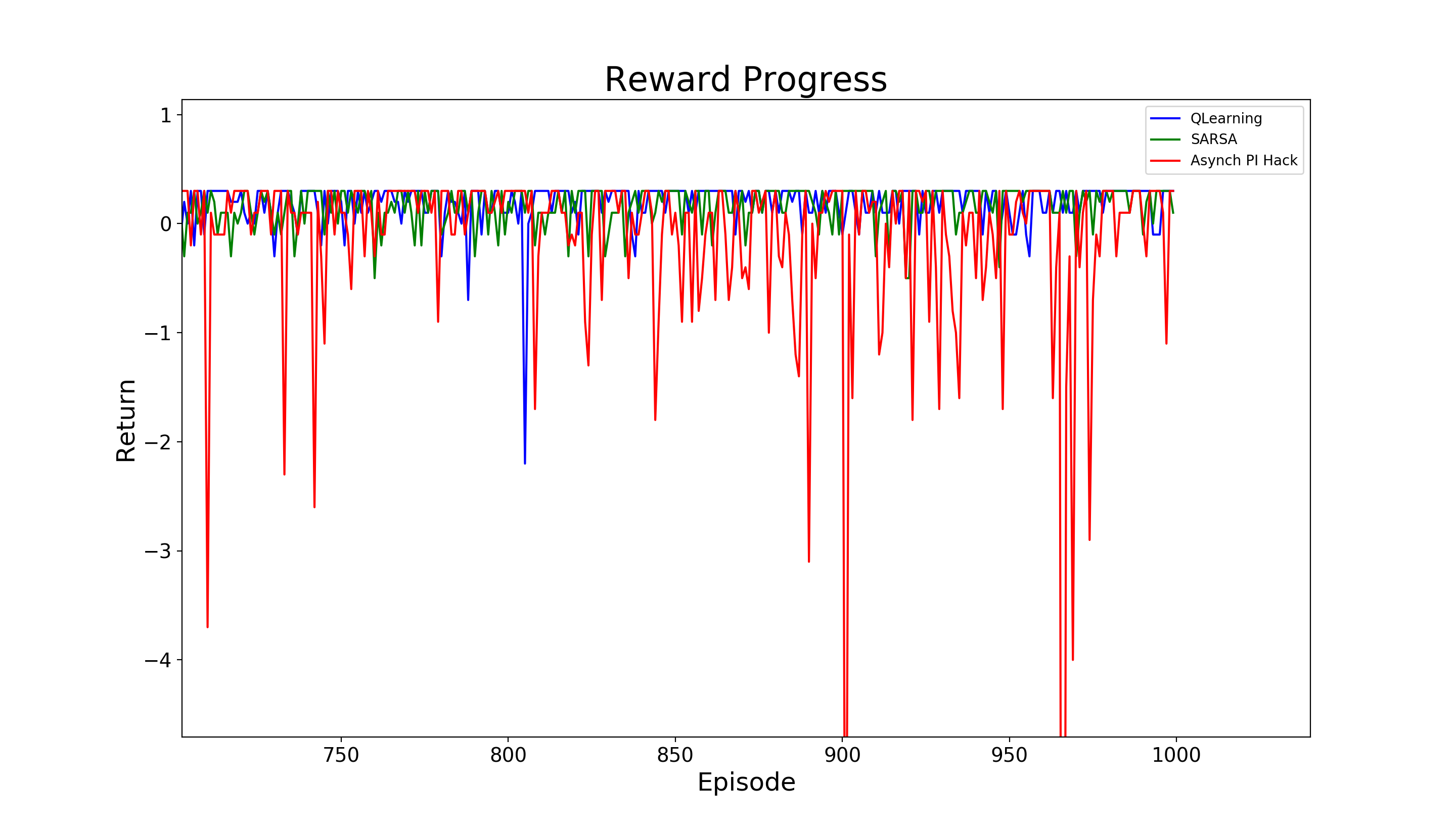
262 KiB
run_main.py
0 → 100644
task1.png
0 → 100644
{kind=link}

256 KiB
task2.png
0 → 100644
{kind=link}

257 KiB
task3.png
0 → 100644
{kind=link}

262 KiB